





Machine learning kan helpen om veel sneller nieuwe, bioactieve moleculen te identificeren. Aan chemici de taak om de suggesties te interpreteren. ‘Je model is zo goed als de data die je gebruikt voor de training.’
Het kantoor van Francesca Grisoni is ook meteen haar laboratorium. Grisoni is assistant professor in de chemische biologie groep van Luc Brunsveld aan de TU Eindhoven, waar ze de onderzoeksgroep Molecular Machine Learning leidt. ‘Wij gebruiken machine learning om nieuwe bioactieve moleculen te ontdekken. Daarbij kan het gaan om de novo design, maar ook om de vraag hoe we algoritmen het best kunnen inzetten om uit bestaande databases de meest geschikte moleculen te selecteren’, vertelt Grisoni. Haar werk bevindt zich aan de voorkant van het geneesmiddelenonderzoek. ‘Bij ons draait het nog echt om drug discovery. De targets zijn meestal eiwitten waar we moleculen bij zoeken die ‘iets’ doen met dat eiwit. Dat kan zijn vanuit therapeutisch oogpunt, bijvoorbeeld omdat je een eiwit wil blokkeren. Maar het kan ook zijn dat je een molecuul zoekt om te gebruiken als een probe, een manier om de functie van dat eiwit te onderzoeken.’
Syntax en semantiek
Om die moleculen te vinden, heeft Grisoni methoden nodig die specifiek zijn voor de chemie. Die zijn niet zomaar voorhanden. De grote toepassingsgebieden van machine learning hebben te maken met beeldverwerking en -herkenning, met taalverwerking en vertalen, met sociale netwerken en met zoekgedrag vertalen naar suggesties. Er is heel erg veel, maar deze methoden kun je niet een-op-een gebruiken om je gewenste molecuul te ontwerpen. ‘Net als dat je bij die andere toepassingen helder moet definiëren wat een ‘woord’ is of een ‘mens’, moeten wij definiëren wat een ‘molecuul’ is. Je moet het begrip molecuul vertalen naar iets wat een computer kan herkennen en waar een computer mee kan werken. Dan gaat het bijvoorbeeld om de atomen waar het molecuul uit bestaat, maar ook om de onderlinge verbindingen tussen die atomen en de ruimtelijke structuur van het molecuul.’ Gelukkig hoeft ze het wiel niet opnieuw uit te vinden. ‘We gebruiken ook concepten uit andere velden, maar we moeten ze wel aanpassen. Bijvoorbeeld uit de taalverwerking gebruiken we het idee van strings, die worden ingezet om automatische antwoorden te genereren of suggesties te doen voor het volgende woord. Wij geven moleculen nu ook weer als een string, een stukje tekst. Een volgorde van letters die de atomen weergeven. De syntax is dan de volgorde van de atomen, de semantiek beschrijft de eigenschappen.’ Wat de machine learning systemen van Grisoni vervolgens doen is door heel veel van deze moleculaire strings te bekijken, te leren wat de logische volgorde van de atomen is. ‘Je moet het netwerk trainen om kans te verbinden met volgorde. Dus als je atoom X hebt, is de kans groot dat daarna atoom Y volgt. Net zoals je dat met woorden doet, ook daar zijn er verschillen in de kans dat twee letters na elkaar komen.’
‘De syntax is de volgorde van de atomen’
Moleculaire gelijkenis
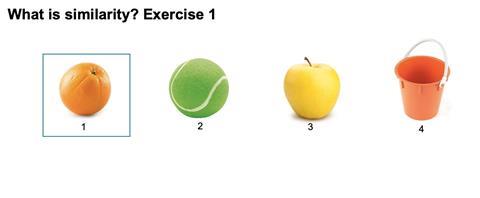
Je zou nog veel meer informatie mee kunnen geven aan het systeem, maar dat doe je bij machine learning nou net niet. ‘Machine learning geeft computers het vermogen om te leren zonder dat ze daarvoor geprogrammeerd zijn. We trainen onze netwerken door ze op grote sets van moleculen los te laten zodat ze patronen gaan zien en zo leren hoe moleculen in elkaar zitten. De volgende stap is dat het netwerk zelf met suggesties voor nieuwe moleculen komt.’ Dat pakt behoorlijk goed uit. Neurale netwerken zoals Grisoni die gebruikt, bleken in staat om na een trainingssessie op een collectie van 300.000 willekeurig verzamelde bioactieve moleculen nieuwe suggesties te leveren, waarvan meer dan 90% valide was. Dat wil zeggen dat die moleculen echt kunnen bestaan. Een bemoedigend begin, maar het doel is natuurlijk om nieuwe moleculen met een specifieke activiteit te ontdekken. ‘Dat gebeurt in de volgende stap. Dan laat je het getrainde netwerk los op een set moleculen die een een gewenste activiteit vertonen om op die manier nieuwe suggesties te verkrijgen. Je maakt hierbij gebruik van structuur-activiteit relaties. Het basale idee is dat als een bepaalde structuur een bepaalde activiteit vertoont, het waarschijnlijk is dat een molecuul met een vergelijkbare structuur ook die activiteit heeft.’ Het netwerk zoekt naar gelijkenissen. Maar wanneer lijken twee moleculen op elkaar en wat bepaalt die gelijkenis het meest? Anders gezegd, welke kenmerken zijn belangrijker dan andere? Dat is niet eenvoudig te bepalen. Voor ons niet, maar voor een computer ook niet. Grisoni, die dit probleem duidelijk vaker heeft uitgelegd, pakt er een plaatje bij van een sinaasappel met daarnaast een groene tennisbal, een gele appel en een oranje emmertje. ‘Welke van die drie lijkt het meest op de sinaasappel? Dat hangt er maar vanaf welke eigenschap je het belangrijkst vindt. Is het de kleur, de vorm of de eetbaarheid?’ Een machine learning systeem kijkt naar al die verschillende moleculen op dezelfde manier en moet dan bepalen wat de meest relevante kenmerken zijn. Daarmee komen we meteen op een van de allerbelangrijkste voorwaarden voor zinvolle machine learning: de kwaliteit van de data waar je het systeem mee laat werken.
‘Machine learning geeft je altijd een antwoord’
Syntheserobots
‘Je model is zo goed als de data die je gebruikt voor je training. Garbage in, garbage out, geldt in ons gebied enorm sterk.’ De ultieme test voor de resultaten van Grisoni’s systemen ligt in de analoge wereld, in het lab. ‘We werken veel samen met de experimentele chemici om onze methoden te valideren en dat betekent de gesuggereerde moleculen maken en testen. Ik wil niet alleen maar methoden ontwikkelen op basis van theorie.’ Maar ook daarvoor ziet ze een meer geautomatiseerde aanpak voor zich door syntheserobots in te zetten. ‘Ons model, het brein, komt met een suggestie, die vervolgens door de robot, de ‘arm’ die het werk doet, wordt gemaakt en getest, waarna de uitkomst weer het model in gaat, waardoor het systeem ervan leert.’ Natuurlijk ziet ze de volgende vraag op zich afkomen. Lachend: ‘Nee, dit betekent niet dat ik denk dat chemici straks overbodig zijn. Maar ik denk wel dat we chemici beter kunnen inzetten voor andere taken, als een robot net zo goed een stof kan maken. Chemici moeten nadenken over wat de uitkomsten betekenen en over de syntheseroutes voor compleet nieuwe moleculen.’ Machine learning kan vooral helpen om veel efficiënter te zoeken naar de juiste moleculen. Maar er zit ook een valkuil in die benadering, waarschuwt Grisoni. Die valkuil zit in het stellen van de goede vraag. ‘Machine learning geeft je altijd een antwoord, maar is het ook het juiste antwoord? Je moet in staat zijn om het antwoord te interpreteren. Daarvoor zijn nog steeds chemici nodig.’










Nog geen opmerkingen